
In this article, you’ll discover how the CACTUS Data Quality Framework helps FP&A teams build trust...

Make Your Data Work for You — The FAIR Framework for FP&A
November 13, 2025

Introduction: Why Data Management Is the Next Step after Data Quality
The previous article, “Get Your Data Right First — The CACTUS Framework for FP&A”, looked at improving the quality of data using the CACTUS framework. Once FP&A teams have improved the quality of their data using a framework like CACTUS, the next challenge is: Can this data be easily found, shared, and reused across regions, tools, processes, and teams?
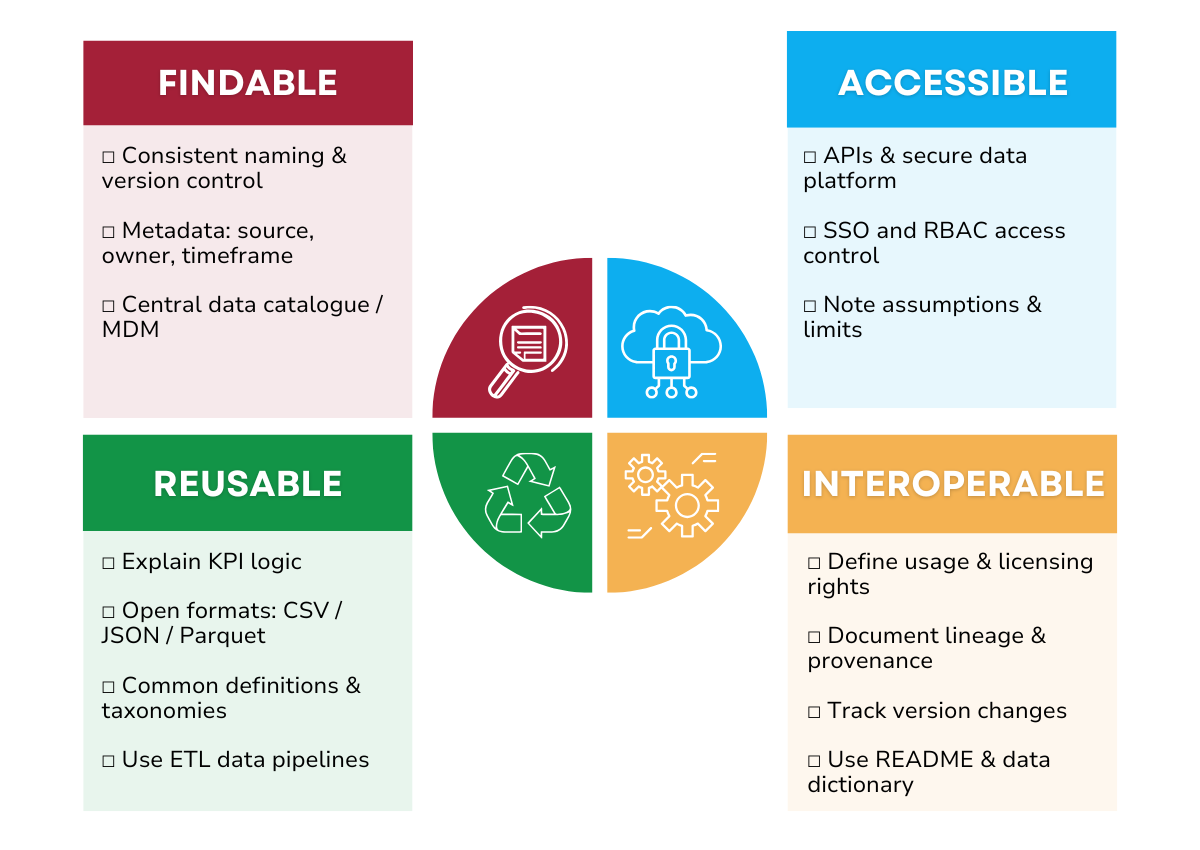
Enter the FAIR data management framework — a set of principles that ensure data is Findable, Accessible, Interoperable, and Reusable for both humans and machines. The FAIR framework (Figure 1) focuses on maximising data utility for analytics and AI.
- F – Findable: Can the right people and systems locate the data quickly?
- A – Accessible: Can they get it, legally and technically?
- I – Interoperable: Can it be used across tools and departments?
- R – Reusable: Is it documented well enough to be used again?
Imagine if you need to integrate financial actuals, forecasts, and external benchmarks across four regions using three different ERP systems. While the data might comply with the six CACTUS data quality dimensions, is it ready to be consumed for analytics and AI with consistent definitions, metadata, or clear documentation? If your data were FAIR, that would be a much easier task. But FAIR isn’t a silver bullet; it is a framework. It doesn’t tell you how to fix your broken financial close process or improve data quality, but it does help make sure that the data is ready for business and finance use-cases.
Applying FAIR in FP&A: Practical Tips
FAIR is not a substitute for data quality. If your data is flawed, making it more visible and accessible through FAIR only amplifies the problems. Think of CACTUS as what’s inside the box — the quality of the data. FAIR, on the other hand, is how that box is labelled, stored, and shared. You need both data quality and data usability. Data should be made usable once the data quality is improved using the CACTUS framework. Specifically follow the FAIR practices below to improve data usability.
A. Findable. In FP&A, time is money, and time spent hunting for data is money burned. Key practices for finding the right data include:
- Use globally unique identifiers such as consistent naming conventions, version control, DOI (Document Object Identifier) and more.
- Tag your datasets and models with metadata: source, owner, format, timeframe, and more. Clearly document who owns the data, who is responsible for its quality and updates, and who to contact for clarification.
- Use searchable repositories such as centralised data catalogues, MDM systems, internal wikis, and more.
B. Accessible. Just because data can be located, doesn’t mean it is accessible. Key practices for data usability are:
- Use standard data access protocols with APIs, secure file shares, SQL endpoints, and so on to access the data in a centralised data platform. A centralised data platform is the cornerstone of modern data management. It eliminates data silos, ensures consistency, and enables more effective data use across the organisation.
- Define who can access what data and make it easy to request permission. Implement secure API gateways, access control via SSO (Single Sign-on), authorisation with RBAC (Role-Based Access Control), and more.
- Assumptions and Constraints: Call out any known assumptions, limitations, or caveats. For example, "data is updated weekly," "values are estimates," or "only covers EU region." These practices help prevent misuse or overgeneralisation of insights.
C. Interoperable. This is needed for breaking silos, enabling agility, and making data usable across the enterprise. Key practices for interoperability are:
- Business Logic: Explain how KPIs are calculated, the semantic meaning of specific data fields, and any business rules or transformations applied to the data. This avoids misinterpretation and ensures consistency in reporting and analytics.
- During data integration, use open and established data formats such as CSV, JSON, and Parquet.
- Use common business definitions such as standardised account hierarchies, product description format, etc. If two departments can’t even agree on what "Revenue" means (orders v/s invoices v/s cash in the bank), forget data integration.
- Apply shared taxonomies and controlled vocabularies such as IFRS/GAPP standards, UNSPSC taxonomies, cost centre definitions.
- Leverage proven ETL (Extract- Transform- Load) tools for building data pipelines for the centralised data platform. An ETL data pipeline is used to move data from multiple sources into a centralised data platform system (like a data warehouse or data lake) for reporting, analytics, and AI.
D. Reusable. Data reusability is the key to speed and scale. When data can be trusted and reused, data adoption improves. Key practices:
- Define and clearly document licensing and usage rights to ensure that all data is used in compliance with organisational policies, legal frameworks, and external regulations. This practice helps protect the organisation and ensures that data can be accessed, shared, and utilised appropriately across different environments — whether for internal use, by external partners, or for business, audit and compliance purposes.
- Provenance and Lineage —who created the data, when, and what logic, version control, and more were used? Include where the data comes from, how it flows through the ETL data pipeline, and what transformations or aggregations it undergoes.
- Versioning and Change History: Track changes to schema, logic, or field definitions over time to help users interpret historical analyses correctly.
- Ensure consistency with community and organisational standards with README templates and data dictionaries. A README template is a predefined structure or format used to create README files to ensure data consistency, clarity, and completeness.
Example: FAIR in Quarterly Forecasting
For example, streamlining quarterly forecasting is a common challenge for most FP&A teams. To make data Findable, they can use consistent naming conventions, add metadata (source, owner, and update frequency), and index all datasets in a searchable data catalogue. For Accessibility, they can store data in a centralised platform with secure APIs, enforced SSO and RBAC, and labelled key assumptions (e.g., exchange rates and geography exclusions). To ensure Interoperability, they can standardise business definitions (e.g., "Revenue" = invoices and not orders or contracts), used open formats like CSV/Parquet, and documented KPI logic and taxonomies (e.g., IFRS hierarchies). For Reusability, the FP&A team can define licensing rules, maintain lineage through ETL pipelines, track schema changes, and use README templates to document logic, owners, and constraints. All this can help the FP&A team dramatically reduce time on wrangling data, improve collaboration across regions, and enable reliable analytics and AI models using consistent, trusted, and well-documented data. The result? Less time wrangling and engineering data, more time generating insights.
Publish and Share — The Final Step
Once the data quality is improved with the CACTUS framework and made more usable using FAIR principles, make data accessible through secure, compliant, and searchable platforms. This ensures that the right people can find and use trusted data efficiently, while meeting governance, privacy, and regulatory standards. Sharing should be intentional and only authorised, and data-literate people should access the data to collaborate across teams, processes, and systems. This step ensures your data drives value — responsibly and efficiently.
Overall, to effectively prepare data for analytics and AI, it is essential to follow a structured, disciplined approach. This process-based CACTUS framework and FAIR principles start with understanding the business need to deploy trusted and usable data assets. Each step builds on the previous one, ensuring that data is not only high in quality but also FAIR for relevancy and usability. Below is a breakdown of the full lifecycle.
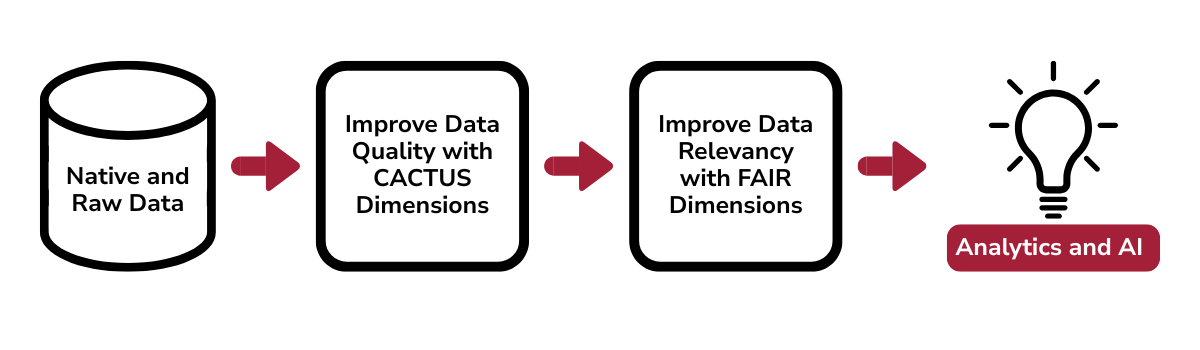
Figure 2. Data Preparation Workflow for Analytics and AI
Conclusion: Why FAIR Complements CACTUS
In the age of AI and analytics, trusted and usable data is your biggest competitive asset. CACTUS ensures trust; FAIR ensures usability. Together, they form a complete roadmap for FP&A teams to prepare data that’s not only accurate and clean but also ready to scale across processes, people, and platforms. By applying the CACTUS and FAIR frameworks, FP&A professionals can reduce inefficiencies, improve forecasting accuracy, and drive smarter, faster decision-making.
About the Author
Dr. Prashanth Southekal is the author of three acclaimed books — Data for Business Performance, Analytics Best Practices, and Data Quality. His second book, Analytics Best Practices, was recognized by BookAuthority in May 2022 as the #1 analytics book of all time, reflecting his global thought leadership in data and analytics.
The full text is available for registered users. Please register to view the rest of the article.
Related articles

Scenario planning in FP&A requires strong data management — from building integrated models to ensuring data...

Integrated FP&A thrives on effective data management — ensuring accuracy, consistency and automation to drive better...

Even if last six years I have been specialized in Data management, I still follow (thanks...

In this article, FP&A professionals discover how soundtracking — the art of blending data, storytelling, and...
+
Subscribe to
FP&A Trends Digest
We will regularly update you on the latest trends and developments in FP&A. Take the opportunity to have articles written by finance thought leaders delivered directly to your inbox; watch compelling webinars; connect with like-minded professionals; and become a part of our global community.