
The concepts of artificial intelligence (AI) and machine learning (ML) are not new. They are relatively...

FP&A Teams Driving Step Changes in Business Performance with AI
June 5, 2019
 FP&A teams are using AI to drive step changes in business performance, pushing their influence beyond their traditional areas of analyses.
FP&A teams are using AI to drive step changes in business performance, pushing their influence beyond their traditional areas of analyses.
A typical ask of the FP&A team is to explain business performance, and that’s never more so than when the business is performing below plan.
Perhaps a machine learning (ML) algorithm can help in these situations to pinpoint the causes of poor performance? Unfortunately, it’s usually not so simple. We often find a mismatch between traditional FP&A datasets and ML algorithms. The latter perform best with large datasets of thousands, if not millions, of transactional records. The consolidated data FP&A teams receive may be far removed from the transactional data, and will typically consist of summary totals. Furthermore, this summary data may contain artefacts of how the Business happens to have organised itself over time e.g. changing business unit structures.
Figure 1 represents what may have happened to transactional business data on its way from “the shopfloor” to the FP&A team. The data will have entered one or more systems, been consolidated, sliced, diced & transformed and then possibly cycled through more systems.
Figure 1: Typical FP&A datasets are far removed from transactional detail
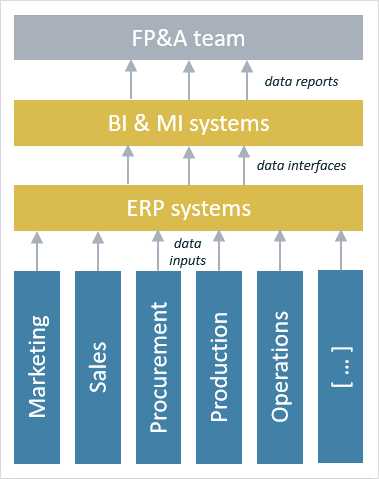
An ML algorithm pointed at this consolidated, restructured data may have its predictive powers overwhelmed by the impact of these artificial structures. To give a (cartoon!) example from another context. Imagine we train an algorithm to recognise human faces, but we first run its training data set through an Instagram filter to give everyone Bugs Bunny ears. The algorithm will place great weight on having long, furry ears, and will then fail miserably to understand real-world faces. Unfortunately, our MI systems’ changing configurations can act in a similar way to distort algorithms’ perception of the underlying reality of business performance.
It would be a waste of data analysis talent if FP&A teams are restricted to their usual datasets. Indeed, some finance teams have felt compelled to step in to guide the business functions in the take-up of advanced analytics, operating on granular, transactional-level data, and in doing so have driven significant improvements in business performance.
Ineffective sales forecasts
A finance team was struggling with the inaccurate sales predictions they were receiving. The team operates in a subscription sales industry with a highly volatile sales profile. The sales predictions were provided by sales teams based at several centres around the world and the predictions’ accuracy was found wanting even for one month out, let alone for 6 months or a year out.
The finance team needed a different approach to sales forecasting. They considered running learning algorithms over the historical sales forecasts from the past few years. They decided, correctly, that the dataset would be too small to take advantage of a machine learning approach. So they went closer to the detailed sales data, and extracted the sales opportunities and the associated probabilities to close which had been hand-scored by the sales teams. Running these historical detailed forecasts of likelihood to close and the outcome consolidated revenues through a learning algorithm gave forecasts with uncertainty ranges slashed to one-fifth of the previous method.
Whilst the finance team was very happy with the performance of their new algorithm, the sales teams were initially suspicious and distrusting: “how can the finance team’s algorithm be better than our own predictions of our sales?” Over time though, the sales teams became comfortable with the predictions. After all, the algorithm was augmenting their capabilities: their strengths lay in understanding individual customers and their likelihood to renew subscriptions, whereas the algorithm was better at predicting the outturn of all these individual probabilities. The sales teams also recognised that with weekly or even daily predictions they could better spot and mitigate slippage within a month. The algorithm even uncovered different behaviours across the sales teams, with some teams being consistently over-optimistic and some over-pessimistic. New guidance was issued by sales management on scoring sales opportunities, and senior management now get like-for-like sales predictions from around the organisation.
High, unexpected losses in consumer credit
A consumer credit firm was part-way through ambitious growth plans for scaling up its loan book. However, it was encountering higher-than-expected losses and it was taking the business 6 months or more to establish the loss pattern for each monthly vintage of loans. Even then the loan term loss forecasts were not granular enough to take meaningful action i.e. they did not show the performance of the loan book by channel partner (retailer) and so could not support useful conversations on how to price loans better and on which risk grades to accept as customers.
The CFO had an intuition that to understand and control losses one has to analyse performance of loans after they are sold, “post-origination”. Using historical data of actual payments behaviour, a model was created that forecast for each loan its monthly status (e.g. 0/30/60/90 days past due, etc.) for the remainder of the loan term.
Figure 2: Transition matrices of customer lifetime journeys can be enhanced with linear regression techniques

The old approach gave a non-granular forecast at six months on book which was on average 150 basis points out from the loan term outturn. The new algorithm gave a per-retailer forecast which at early as two months on book was only around 20 basis points out. These early and granular forecasts were sufficiently accurate to mitigate any poor performance seen with new partner retailers.
This loan-by-loan forecasting approach brought other benefits. Costs could be a better forecast and applied appropriately to each loan. For example, if a loan was forecast to slip into arrears in, say, four months’ time, the associated in-collections costs could also be applied from that point. By building up a forecast of both revenue and costs by loan by month, margin forecasts could then be calculated.
Conclusion
Some people would view the above examples as sitting outside the normal remit of FP&A teams. The reality is that in many companies the FP&A teams are well-placed to champion the use of machine learning and artificial intelligence: they have the data analysis mindset to be open to the appropriate use of these technologies.
Traditional FP&A datasets can be insufficient to take advantage of the full capabilities of machine learning algorithms to explain and drive business performance. Unfortunately, the business functions which have the granular data don’t always step up to analyse their own data with newer techniques.
This is where FP&A teams can act as an agent for change, and can drive significant improvements in business performance.
Some push-back can be expected from the business functions but, handled sensitively, FP&A teams can help encourage a wider and effective take-up of AI through the business.
The full text is available for registered users. Please register to view the rest of the article.
Related articles

In July 2017, I presented at the 2017 AICPA FP&A Conference in Las Vegas over AI...
+
Subscribe to
FP&A Trends Digest
We will regularly update you on the latest trends and developments in FP&A. Take the opportunity to have articles written by finance thought leaders delivered directly to your inbox; watch compelling webinars; connect with like-minded professionals; and become a part of our global community.