
The concepts of artificial intelligence (AI) and machine learning (ML) are not new. They are relatively...

Experiences from Implementing Machine Learning for Forecasting
May 8, 2019
By Asif Khan, Global FP&A at PayU
 The democratization of technologies is underway. Tools like machine learning (ML), which were confined to universities, hedge funds or investment banks just until a decade ago, are now finding their way into industry-wide applications. The finance function is set to reap the benefits of this democratization wave.
The democratization of technologies is underway. Tools like machine learning (ML), which were confined to universities, hedge funds or investment banks just until a decade ago, are now finding their way into industry-wide applications. The finance function is set to reap the benefits of this democratization wave.
In PayU's finance function, we decided to test ML’s effectiveness in forecasting the financials in 2017.
Below I share our thought process about WHY and HOW we went about implementing ML-based models for forecasting.
Starting with WHY
The first step of the path towards implementing ML in finance function was to understand the WHY? As Simon Sinek puts it in his hugely viral video “Start with Why”.
Before starting with ML-based forecasting, we were doing bottom-up forecasting on a monthly basis. To arrive at a forecast, finance teams of different regions/countries had discussions with commercial teams, performed pipeline analysis and seasonality checks, etc.
However, the results of the forecast were suboptimal due to four key factors:
- Industry growth: PayU operates in Fintech and payments industry where some markets are growing substantially on a yearly basis which makes forecasting difficult. Therefore, the bottom-up forecast results for these hyper-growth markets were off significantly – sometimes even by 5-10% variance for the upcoming quarter.
- Drivers: The above is explained to an extent by the fact that the industry is relatively new and therefore business drivers are not always fully clear. While doing bottom-up forecasting, the regions and countries were taking mostly internal drivers as inputs, while there was less focus on external drivers.
- Time taking exercise: The bottom-up forecasting is manual. It requires inputs from multiple departments and significant man-hours from start to finish.
- Biases: Biases feed into the forecasting process. For example, a commercial team member might be too aggressive or pessimistic on the growth expectations.
Hence, our WHY to implement ML-based models was to improve the accuracy levels and speed of forecasting while reducing the time needed to come to forecast.
Proceeding with HOW
We took a very agile approach to ML model implementation in our company and did not go all in on ML with a lot of resources. The idea was to come with prototype versions of ML models and test if there is some real merit in using these models. The criterion of success of the prototype was very simple: Can the prototype models forecast better than bottom-up process?
Step 1. Forming a small team. Having engineers in finance team helped on the journey to a prototype. We also sought help from tech team members on a part-time basis. Since machine learning was a new area for us all, we took self-learning classes from some of the fantastic courses available on leading online learning platforms.
Step 2. Data preparation. We had data sitting in silos. Connecting all the data sources, cleaning it, removing the outliers and then making a useable and clean data repository was a crucial step.
Step 3. Implementation. Finally, we managed to start implementing ML algorithms on the processed data sets. We divided the data into 2 sets: (i) Training data: to train the ML models, and (ii) Test data: To test the trained models on actual historical data. This helped us to increase our confidence in the predictive power of the models.
Results: It took us around 3 months to have a prototype version of the ML models. This timeframe really depends on the complexity of each individual companies, and the purpose of usage.
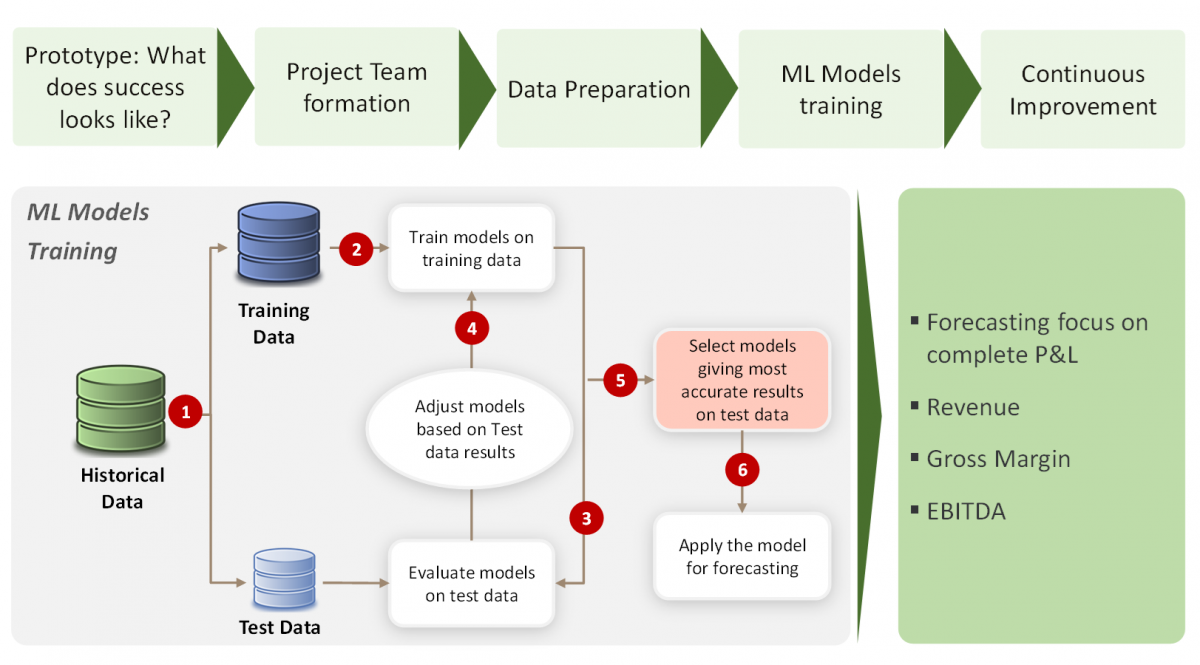
Figure 1: Architecture supporting ML Project for forecasting
Benefits achieved in the first 3 months
In our case, using ML models for forecasting lived up to the expectations.
We used these models to forecast revenue, gross margin and EBITDA. These models also provided several benefits across accuracy, speed and flexibility:
- Accuracy: The forecast variance versus actuals using ML models was down to less than 2% even in case of difficult to forecast markets where we earlier had a variance of 5-10%. With our high growth rates, this is a substantial improvement
- Speed: Complete bottom-up forecasting took us in some cases almost a week. Now using the trained ML models, we can perform robust forecasting in a day
- Flexibility: Using ML algorithms enabled us to: (i) test number of drivers relatively quickly, and (ii) helped in process of driver discovery – or finding new drivers which we were unaware of. We can also quickly consider and test more drivers – both internal and external. This improves the understanding of business and sometimes helps give early warning signs
Conclusion
Our initial foray into using ML capabilities for forecasting has been successful. ML models are data hungry, so we have continued to enrich our models and are still testing them to get better accuracy levels. We will also be creating new models for products which were not in scope for the prototype version.
Our experience with implementing ML models for forecasting has encouraged us to also look at other processes within the finance function where ML can be used to full advantage.
The full text is available for registered users. Please register to view the rest of the article.
Related articles

In July 2017, I presented at the 2017 AICPA FP&A Conference in Las Vegas over AI...

In this article, the author explores top 3 impacts of AI & ML on FP&A people, processes and...
+
Subscribe to
FP&A Trends Digest
We will regularly update you on the latest trends and developments in FP&A. Take the opportunity to have articles written by finance thought leaders delivered directly to your inbox; watch compelling webinars; connect with like-minded professionals; and become a part of our global community.